今天再复习下深度学习里一个有点反直觉的现象,以及一个天才般的解决方案——残差网络(ResNet)。这可不是什么冷冰冰的技术名词堆砌,而是一个关于“如何让机器学得更聪明”的真实故事。
一个让研究者挠头的实验——越深反而越差?
想象一下,你是个深度学习研究员,时间是2015年左右,那时大家有个共识:网络层数越多,模型能力应该越强。就像盖楼,20层总比5层视野好、容量大吧?于是大家拼命堆叠卷积层,VGG网络都干到19层了。
但微软亚洲研究院的何恺明团队做了个实验,结果让人大跌眼镜:
他们训练了一个20层的普通卷积网络(就是一层层叠上去那种)在ImageNet图像识别数据集上。
然后,他们又训练了一个结构几乎一模一样,只是更深(56层)的网络。
你猜怎么着?这个56层的“摩天大楼”,不仅在测试集上表现不如20层的(这可能是过拟合),更关键的是,它在训练集上的错误率居然也比20层的更高!
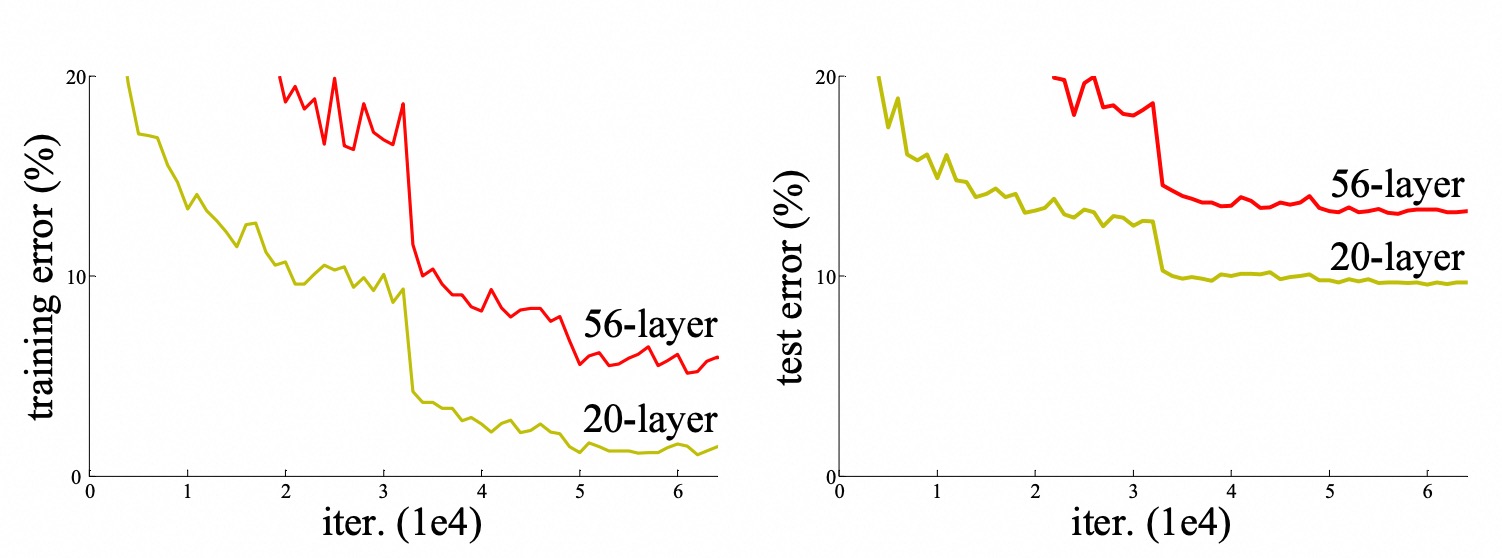
(示意图:深层网络(56 层)的训练误差和测试误差反而高于浅层网络(20 层))
这就太诡异了! 按理说,训练集是模型可以“死记硬背”的,更深的网络拥有更多的参数和表达能力,它应该至少能把训练数据拟合得很好,甚至完美记住(过拟合)。但事实是,它连“记住”都做不到,训练误差都降不下去。
这种现象被称作“网络退化”(Degradation)。 它不是过拟合,而是模型根本训练不好了。就好像你给一个学生更厚的练习册(更多层),期望他成为学霸,结果他连之前薄练习册上的题都做不对了!问题出在哪?
病根探寻——深度模型的“失忆症”与“学废了”
为什么更深的网络反而学不好了呢?研究者们排除了过拟合(因为训练集表现就差),发现问题核心在于优化困难。
打个接地气的比方:
浅层网络(比如20层): 像是一个经验丰富的老师傅带20个徒弟组装一辆自行车。每个徒弟(网络层)负责一小块,流程清晰,老师傅(优化器,如梯度下降)能清楚地指导每个人该怎么做,哪里没装好就调整哪里。最终自行车顺利装好。
深层网络(比如56层): 现在变成了56个徒弟来装这辆自行车。流程变得极其复杂冗长。老师傅站在队伍末尾指挥:
他对队伍最前面(浅层)的徒弟喊话:“你那个螺丝拧太紧了!” 声音(梯度)要经过55个人传递才能到前面,中间可能被误解、被忽略、甚至传丢了(梯度消失/爆炸)。
更糟糕的是,这56个人里,可能有一部分人根本就是多余的!理想情况下,他们应该“什么都不做”,直接把前一个人的活儿原封不动传给下一个人(即实现
输出 = 输入,这叫恒等映射)。但问题来了:让一个由好几道复杂工序(卷积、非线性激活)组成的“小团队”实现“什么都不做”,比让它“做点什么”还要难!想想看:要求一个拿着扳手、螺丝刀,习惯拧来拧去的工人(一层非线性变换),现在必须精准地做到“手别抖,别多拧一下,也别少拧一下,确保输出和输入一模一样”。这要求太苛刻了!稍微有点误差,后面层层累积,结果就歪了。
这就是深层普通网络退化的核心病根:
信息/指令传递不畅: 梯度(老师傅的指令)在深海中衰减或混乱。
冗余层成为负担: 要求那些本应“躺平”(做恒等映射)的层精准“躺平”,对深度非线性模型来说,是极其困难的优化目标。优化器(老师傅)被这个高难度动作搞懵了,结果连基本的任务(拟合训练数据)都完成不好。
ResNet的妙手回春——学“差距”而非学“全部”
面对这个死胡同,何恺明团队提出了一个极其聪明又简单的想法:残差学习(Residual Learning)。这就是ResNet的核心。
核心思想转变:
传统网络学什么? 直接学习从输入
x到理想输出H(x)的完整映射H(x) = SomeComplexFunction(x)。对于冗余层,H(x)理想值就是x。残差网络学什么? 不再硬啃
H(x),而是学习理想输出 H(x)和输入 x之间的差距(残差),记作F(x) = H(x) - x。然后,网络的实际输出设计为:H(x) = F(x) + x。
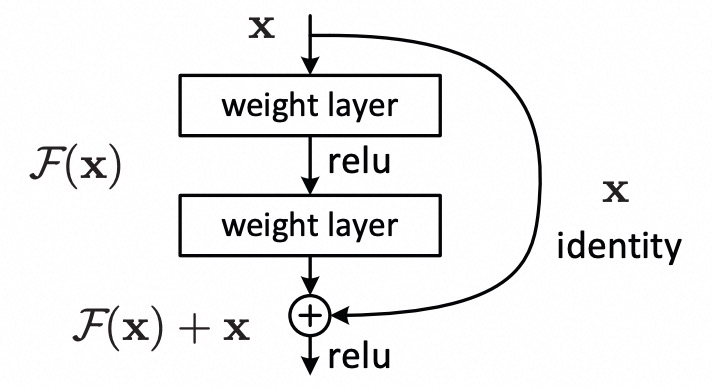
(残差块结构:输入x走两条路,一条被变换F(x),一条直接“抄近道”,最后加起来)
这个简单的“抄近道”(Shortcut Connection 或 Identity Mapping)设计,带来了革命性的变化:
化“不可能”为“可能” - 解决冗余层难题:
对于那个应该“躺平”的冗余层,它的理想任务是
H(x) = x。在残差块里,这等价于要求
F(x) = H(x) - x = x - x = 0。让一个复杂的函数
F(x)(由几层卷积和非线性组成)去逼近0,比让它去精确逼近x容易太多了!为什么?想象要求工人“啥也别干”(输出0),他只需要把工具放一边(权重初始化为接近0)或者做点极其微小的调整(输出接近0)就大致做到了。即使他做得不完美(
F(x)不完全等于0),只要别太离谱,加上“抄近道”过来的原始x,最终输出H(x) = F(x) + x ≈ x也不会太差。总结: 残差结构把冗余层的高难度目标(精确恒等映射) 转化为了低难度目标(逼近零函数),大大降低了优化器的负担。这就是解决“网络退化”的关键魔法!
给梯度装上“保命符” - 缓解梯度消失:
反向传播计算梯度(误差如何指导每层参数更新)时,残差块的结构带来了天然优势。
计算输出
H(x)对输入x的导数(梯度传播的关键一步):dH/dx = d[F(x) + x]/dx = dF/dx + 1这个
+1是神来之笔!即使F(x)部分的梯度dF/dx因为网络太深变得非常非常小(甚至接近0),这个+1也能保证总梯度dH/dx至少有一个稳定的“底线”(不小于1),能把误差有效地、至少以“1倍”的强度回传到更浅的层。 这就像在深井里垂下一根坚固的安全绳(+1),即使旁边的梯子(dF/dx)年久失修快断了,人(梯度)也能顺着安全绳爬上来(传回去),避免了在深层“饿死”(梯度消失)。
残差连接的“意外之喜”
解决了核心的退化和梯度问题,ResNet还带来了一些锦上添花的优点,让深度模型真正起飞:
特征复用的“高速公路”: “抄近道”的连接让浅层提取的低级特征(如边缘、纹理、颜色)能直接“走高速”到达深层,和高层提取的语义特征(如“车轮”、“猫耳朵”)汇合。深层网络不用再费劲地从头去识别这些基础特征了,效率更高,特征更丰富。
更“平坦”的训练地形: 当残差块
F(x)初始化为接近0(这是很容易做到的),整个网络的起始状态就是H(x) ≈ x,这是一个相对合理的起点(相当于一个浅层网络)。研究表明,这种结构使得损失函数(优化目标)的“地形”更平滑,优化器(如SGD)更容易找到下山的路,收敛更快更稳。对初始化不那么“娇气”: 传统深度网络对权重初始值非常敏感,初始不好就容易崩。ResNet因为有“抄近道”保底(初始
H(x)≈x),即使F(x)部分初始化得不太理想,也不至于完全崩溃,训练更鲁棒。智能的“动态深度”: 有研究观察到一个有趣现象:对于简单的图片(比如一张纯色背景的猫),信息可能主要走“抄近道”,只经过少量
F(x)变换就输出了;对于复杂的图片(比如人群中的猫),信息则会利用更多的F(x)块进行深度处理。网络似乎能自己决定用多“深”来处理不同的输入,更智能高效。
余音绕梁——残差思想的启示
ResNet的成功绝非偶然。它于2015年横空出世,横扫ImageNet等多项竞赛,让训练成百上千层的网络成为可能(如ResNet-152, ResNet-1000),彻底改变了深度学习的格局。何恺明也因此获得2016年CVPR最佳论文(实至名归)。
但ResNet留给我们更深层次的启示是什么呢?
它展现了一种解决复杂系统问题的绝妙哲学:当你面对一个难以直接达成的宏伟目标(深层高性能网络)时,不妨将其拆解。不再强求每个部分都完成不可能的任务(让每层都精确传递或变换),而是允许系统“偷个懒”(恒等映射),聚焦于学习需要做出的“修正”(残差)。通过降低局部优化的难度(学残差比学完整映射容易),反而成就了全局的卓越。
这种“学差距(Delta)”的思想,不仅在AI领域影响深远(Transformer里的Add & Norm层、各种Norm层、甚至扩散模型都有它的影子),也启发我们在工程、管理乃至生活中思考:有时候,追求完美的“从零构建”不如聪明的“迭代改进”;给系统留一条“保底”的退路,往往能走得更远、更稳。
下次当你看到“残差网络”这个词,希望你能想起这个关于“深度困境”、“抄近道”的智慧、以及“学差距”的哲学的小故事。它不仅是技术的突破,更是思维的闪光。
参考文献
[1] He K , Zhang X , Ren S ,et al.Deep Residual Learning for Image Recognition[J].IEEE, 2016.DOI:10.1109/CVPR.2016.90.